Four Dots Research
AI Hallucinations Are Costing Businesses $67.4 Billion a Year
Every major AI model fabricates information. The business losses are accelerating. This is one of the reasons we built Suprmind.
What This Page Covers
Listen to the full research (51 min)
If your agency uses AI for content creation, client reporting, strategy recommendations, or research, some percentage of what those tools produce is fabricated. Not "a little off." Not "needs editing." Fabricated. Invented statistics. Nonexistent sources. Fake case studies cited with full confidence.
The AI doesn't flag it. It doesn't say "I made this up." It delivers the fabrication with the same tone and certainty it uses for verifiable facts. And unless someone catches it, that fabrication flows into a client deliverable, a strategic recommendation, or a published article under your agency's name.
We've been running Four Dots as a digital marketing agency since 2013. We've built six proprietary tools across that time. We use AI across every part of our operation. And after watching the hallucination problem compound - in our own work and in our clients' - we built Suprmind, a multi-AI chat platform designed to have least hallucinations, compared with single models.Suprmind mitigates hallucinations by running your question through five frontier AI models, that share the same context, and read each other’s answers. When one model hallucinates, the others catch and correct it before it reaches your decision.
This page explains the scale of the problem, where the real damage is happening, why it can't be "fixed" in any traditional sense, and what we're doing about it. The data below draws from our comprehensive hallucination research - the full benchmark tables, model-by-model breakdowns, and 57 academic and industry sources are published at Suprmind's Hallucination Rates and Benchmarks reference page.
What AI Hallucinations Actually Are
An AI hallucination is when a model generates information that is factually wrong and presents it as true. It doesn't hesitate. It doesn't qualify. It produces invented statistics, fabricated legal citations, nonexistent research papers, and fictional case studies with the same linguistic confidence it uses to tell you the capital of France.
There are two types worth distinguishing.
Faithfulness hallucination. The model contradicts information it was explicitly given. You hand it a contract and ask for a summary - it adds clauses that don't exist in the original document. You give it a client report and ask for highlights - it invents data points that aren't in the file.
Factuality hallucination. The model generates information that has no basis in reality whatsoever. It invents statistics, cites papers that don't exist, references court cases that never happened. No source material was contradicted because no source material was consulted.
The confidence paradox. MIT researchers found in January 2025 that AI models use more confident language when hallucinating than when stating facts. Models were 34% more likely to use phrases like "definitely" and "without doubt" when generating incorrect information. [5]
The wronger the AI is, the more certain it sounds.
Why it happens. Large language models are prediction engines, not knowledge bases. They generate text by predicting the most statistically probable next word based on patterns in their training data. They don't understand truth. They predict what sounds plausible. When the model hits a gap in its training data, it fills that gap with something that reads well rather than admitting it doesn't know. [1]
The Business Cost Nobody Is Tracking
Most organizations using AI have no structured process for measuring the cost of hallucination-driven errors. The failures are quiet. The system looks like it's working. The output reads well. The damage surfaces weeks or months later, usually attributed to something other than "the AI made it up."
The aggregate numbers are staggering:
| Metric | Value | Source |
|---|---|---|
| Global business losses (2024) | $67.4 billion | AllAboutAI, 2025 |
| Executives using unverified AI content for decisions | 47% | Deloitte, 2025 |
| AI production bugs from hallucination | 82% | Testlio, 2025 |
| Customer service bots requiring rework | 39% | Testlio, 2024 |
| Employee time verifying AI output per week | 4.3 hours | Forbes/AllAboutAI |
| Annual verification cost per employee | $14,200 | Forrester, 2025 |
| Companies with investor confidence drops from AI errors | 54% | Industry reports |
| Enterprise AI policies with hallucination protocols | 91% | AllAboutAI, 2025 |
| Hallucination detection market growth (2023-2025) | 318% | Gartner, 2025 |
| Investment in hallucination-specific solutions | $12.8 billion | AllAboutAI, 2023-2025 |
Sources: AllAboutAI [1], Deloitte Global AI Survey [2], Forrester Enterprise AI Cost Analysis [3], Testlio AI Testing Report [4], Gartner [6]
The Verification Tax
Here's the number that should concern every agency owner: employees spend an average of 4.3 hours per week verifying whether AI-generated content is accurate. That's more than half a working day, every week, spent checking AI's homework. [3]
At scale, that verification burden costs approximately $14,200 per employee per year. For an agency with 30 people using AI tools, that's $426,000 annually in pure overhead that produces zero deliverables. [3]
And that's among organizations that know to check. The scarier figure is the 47% of executives who made major decisions based on AI content they never verified at all. [2]
When one AI hallucinates, four others catch it.
Suprmind runs your question through five frontier AI models. Each one sees what the others said. Disagreement gets surfaced, not buried.
Try Suprmind FreeSee the full hallucination benchmark data -->
Where It Hurts Most: Hallucination Rates by Industry
Hallucination rates are not uniform. A model that performs well on general knowledge can be dangerously unreliable on legal questions. The domain your agency operates in - or the verticals you serve - determines how much risk you're carrying.
| Knowledge Domain | Top Models | All Models Average |
|---|---|---|
| General Knowledge | 0.8% | 9.2% |
| Historical Facts | 1.7% | 11.3% |
| Financial Data | 2.1% | 13.8% |
| Technical Documentation | 2.9% | 12.4% |
| Scientific Research | 3.7% | 16.9% |
| Medical / Healthcare | 4.3% | 15.6% |
| Coding and Programming | 5.2% | 17.8% |
| Legal Information | 6.4% | 18.7% |
Source: AllAboutAI, 2025 [1]
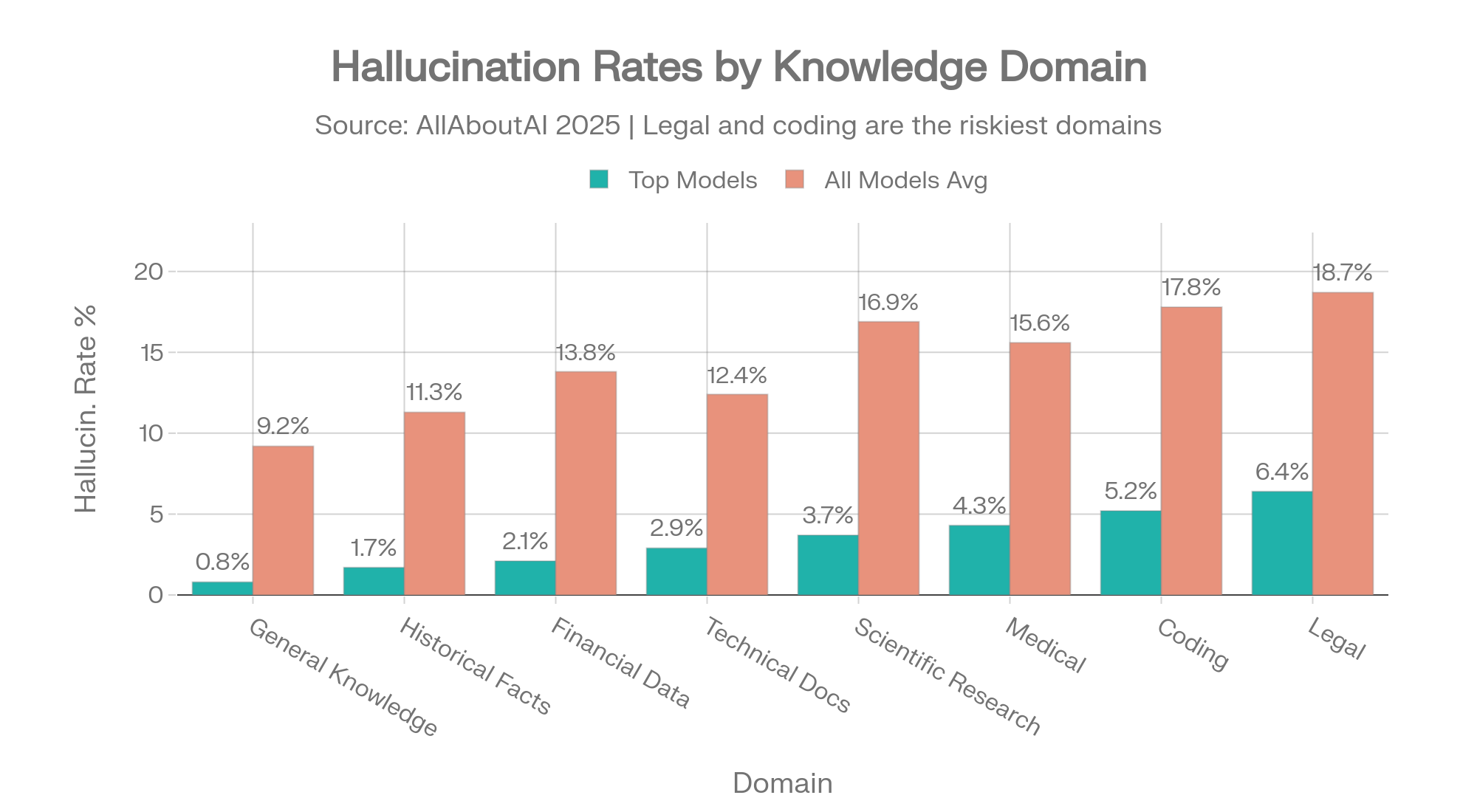
Domain-specific hallucination rates: top models vs. all-model average. The 3x gap in Legal and Coding shows how much model selection matters. Source: AllAboutAI [1]
The gap between the best model and the average model tells you how much model selection matters. On legal information, the best models hallucinate 6.4% of the time. The average model hallucinates 18.7%. That's a 3x difference in reliability based on which AI you happen to be using.
For agencies serving clients in legal, healthcare, or financial verticals, this is not a quality concern. It's a liability concern.
The Full Picture: No Single Model Wins
The table below is our master cross-benchmark reference - every frontier AI model measured across six independent evaluation frameworks. The takeaway is immediate: a model that scores well on one benchmark can score terribly on another. There is no single "best AI," and anyone claiming otherwise is cherry-picking which benchmark to cite.
Column guide: Vectara (Old/New) measures summarization faithfulness (lower = better). AA-Omni Acc is accuracy on hard knowledge questions (higher = better). AA-Omni Hall is how often the model fabricates instead of refusing (lower = better). FACTS is multi-dimensional factuality (higher = better). HalluHard is hallucination in realistic conversations (lower = better). CJR Citation is citation accuracy for news sources (lower = better).
| Model | Provider | Vectara (Old) | Vectara (New) | AA-Omni Acc | AA-Omni Hall | FACTS | HalluHard | CJR Citation |
|---|---|---|---|---|---|---|---|---|
| GPT-5.2 (xhigh) | OpenAI | – | 10.8% | 43.8% | ~78% | 61.8 | 38.2% | – |
| GPT-5 | OpenAI | 1.4% | >10% | 40.7% | – | 61.8 | – | – |
| GPT-5.1 | OpenAI | – | – | 37.6% | 81% | 49.4 | – | – |
| GPT-4.1 | OpenAI | 2.0% | 5.6% | – | – | 50.5 | – | – |
| o3-mini-high | OpenAI | 0.8% | 4.8% | – | – | 52.0 | – | – |
| Claude 4.1 Opus | Anthropic | – | – | – | 0% | 46.5 | – | – |
| Claude Opus 4.6 | Anthropic | – | 12.2% | 46.4% | – | – | – | – |
| Claude Opus 4.5 | Anthropic | – | – | 45.7% | 58% | 51.3 | 30% | – |
| Claude Sonnet 4.6 | Anthropic | – | 10.6% | 40.0% | ~38% | – | – | – |
| Gemini 3.1 Pro | – | 10.4% | 55.3% | 50% | – | – | – | |
| Gemini 3 Pro | – | 13.6% | 55.9% | 88% | 68.8 | – | – | |
| Gemini 2.0 Flash | 0.7% | 3.3% | – | – | – | – | – | |
| Grok 4 | xAI | 4.8% | >10% | 41.4% | 64% | 53.6 | – | – |
| Grok 4.1 Fast | xAI | – | 20.2% | – | 72% | 36.0 | – | – |
| Grok-3 | xAI | 2.1% | 5.8% | – | – | – | – | 94% |
| Perplexity Sonar Pro | Perplexity | – | – | – | – | – | – | 37% |
| DeepSeek-R1 | DeepSeek | 14.3% | 11.3% | – | 83% | – | – | – |
| Llama 4 Maverick | Meta | 4.6% | – | – | 87.6% | – | – | – |
Sources: Vectara HHEM Leaderboard [1], Artificial Analysis AA-Omniscience [22], Google DeepMind FACTS [3], HalluHard [5], Columbia Journalism Review [6]. Dashes = no published data. Full model-by-model analysis: Suprmind Hallucination Benchmarks
Read across any row. Grok-3 scores an excellent 2.1% on Vectara summarization but 94% on CJR citation accuracy. Gemini 3 Pro has the highest factuality score (68.8 on FACTS) but an 88% hallucination rate when it doesn't know an answer. Claude 4.1 Opus achieves 0% hallucination on AA-Omniscience by refusing to guess - but doesn't appear on most other benchmarks. There is no "safest AI." There is only the question of which failure mode you're exposed to.
The Legal Crisis: AI Hallucinations in Court
The acceleration of AI hallucinations in legal filings is the starkest example of what happens when fabricated AI output enters high-stakes environments without verification.
The Numbers Are Getting Worse
| Year | Court Rulings Involving AI Hallucinations |
|---|---|
| 2023 | 10 documented rulings |
| 2024 | 37 documented rulings |
| First 5 months of 2025 | 73 documented rulings |
| July 2025 alone | 50+ cases |
Sources: Business Insider [8], Charlotin Legal Citation Hallucination Database [7]
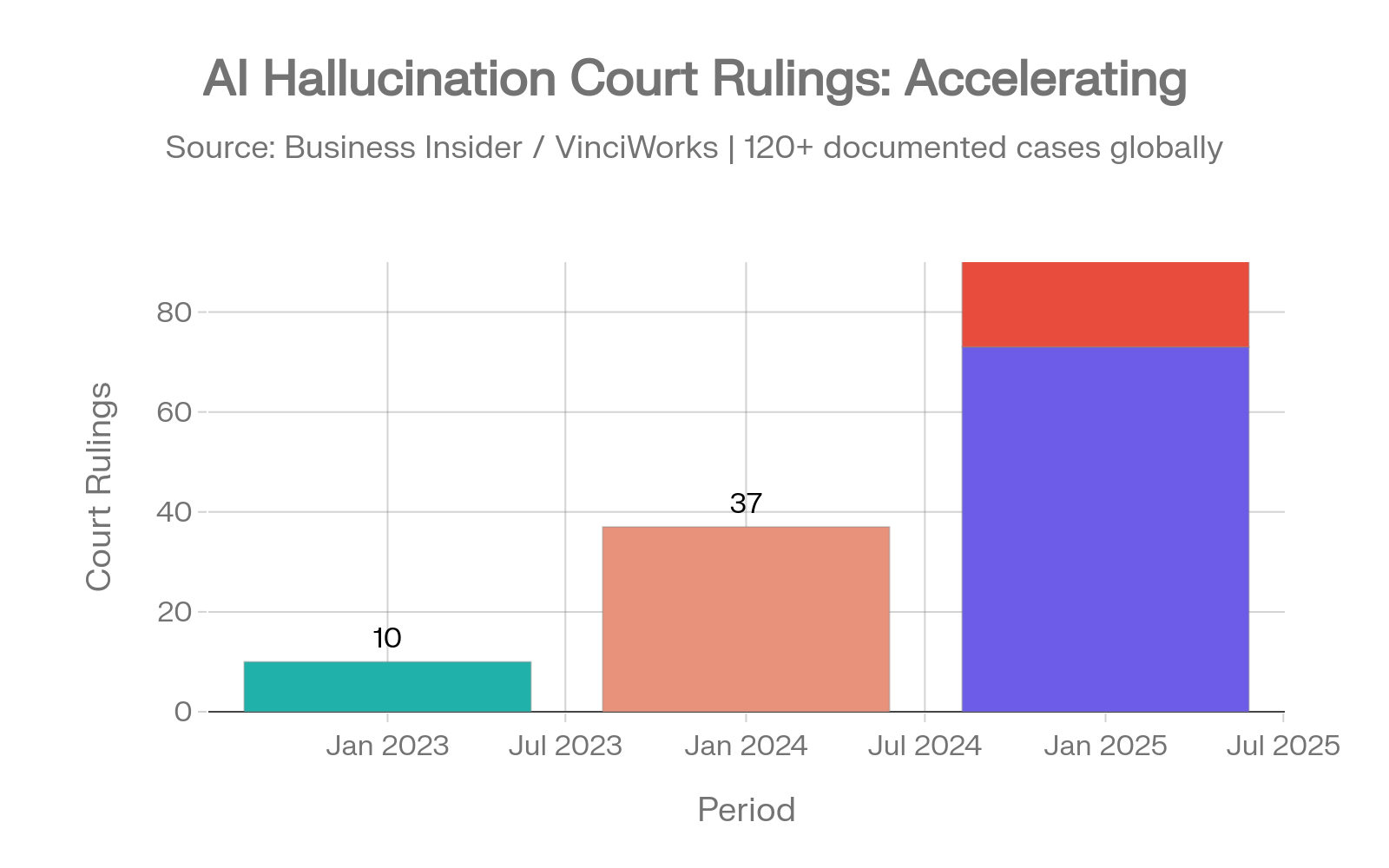
Legal AI hallucination court cases: the acceleration from 10 to 37 to 73 to 50+ cases. Sources: Business Insider [8], Charlotin [7]
Legal researcher Damien Charlotin has documented over 120 cases where courts found AI-hallucinated quotes, fabricated case citations, or invented legal precedents. [7]
This is no longer an amateur problem. In 2023, most hallucination cases involved self-represented litigants. By May 2025, 13 of 23 caught cases came from practicing lawyers. Morgan and Morgan, one of America's largest personal injury firms, sent an urgent warning to more than 1,000 attorneys after sanctions threats for AI-generated citations. Courts have imposed monetary sanctions exceeding $10,000 in at least five cases - four of them in 2025. [8]
Stanford RegLab and the Stanford Human-Centered AI Institute found that LLMs hallucinate between 69% and 88% on specific legal queries. Even purpose-built legal AI tools fail: Lexis+ AI produced incorrect information more than 17% of the time, and Westlaw AI-Assisted Research hallucinated more than 34%. [9]
For agencies serving law firms. If your clients use AI for any research, drafting, or analysis that touches legal questions, the hallucination rate on those specific tasks runs 6x-10x higher than general knowledge queries. Presenting these statistics to legal clients - alongside a verification solution - is a real service opportunity.
Healthcare and Financial Risks
Healthcare: Where Hallucinations Can Kill
ECRI, the global healthcare safety nonprofit, listed AI risks as the number one health technology hazard for 2025. [10]
The FDA has authorized 1,357 AI-enhanced medical devices - double the figure from end of 2022. Of those, 60 devices were involved in 182 recalls, with 43% of recalls happening within the first year of approval. [11]
A 2025 MedRxiv study measured hallucination rates on clinical case summaries: 64.1% without mitigation, dropping to 43.1% with structured prompting. Even the best-performing model (GPT-4o) hallucinated 23% of the time with mitigation active. Open-source models exceeded 80%. [12]
Finance: Quiet Failures with Loud Consequences
78% of financial services firms now deploy AI for data analysis. Without safeguards, hallucination rates on financial tasks run 15-25%. Firms report 2.3 significant AI-driven errors per quarter, with individual incident costs ranging from $50,000 to $2.1 million. [13]
67% of VC firms use AI for deal screening, but the average time to discover an AI-generated error is 3.7 weeks - often too late to reverse a decision. The SEC imposed $12.7 million in fines for AI misrepresentations across 2024-2025. [13]
For agencies. The cost per major hallucination incident ranges from $18,000 in customer service to $2.4 million in healthcare malpractice. Even at the low end, a single unverified AI output that reaches a client deliverable can cost more than a year of prevention tools. [1]
Why Zero Hallucination Is Mathematically Impossible
This section matters because it changes the question. Most people assume hallucination is a bug that will be patched in the next model release. It's not. Two independent research teams have mathematically proved it.
Proof 1: Hallucination Is Built Into the Architecture
Xu et al. (2024) formalized the problem and proved that eliminating hallucination in large language models is impossible. Not difficult. Not requiring more compute. Mathematically impossible given the fundamental design of how these systems generate text. Any system that produces text by predicting probable sequences from statistical patterns will, by mathematical necessity, sometimes produce outputs not grounded in fact. [14]
Proof 2: Four Goals That Cannot All Be True
Karpowicz (2025) attacked the problem from three different mathematical frameworks and reached the same conclusion each time. No language model can simultaneously achieve all four of these properties: [15]
- Always producing factually correct output
- Preserving the meaning of source material
- Surfacing relevant stored knowledge
- Staying within the bounds of what it actually knows
You can optimize for any three. You cannot get all four. The math doesn't allow it.
OpenAI Agrees
OpenAI publicly acknowledged these findings and identified three mathematical factors that make hallucination permanent: epistemic uncertainty (information appearing rarely in training data), model limitations (some tasks exceeding what the architecture can represent), and computational intractability (certain verification problems being too hard even for theoretical superintelligence). [16]
This changes the question. The right question is no longer "which AI doesn't hallucinate?" Every AI hallucinates. The right question is: what system do you have in place to catch hallucinations before they reach a client deliverable?
What Actually Reduces Hallucination - Ranked by Evidence
Not all mitigation techniques are equal. Some have strong measured data behind them. Others are theoretical. This ranking reflects the evidence base, not marketing claims.
1. Web Search Access - 73-86% Reduction
The single highest-impact intervention. GPT-5 drops from 47% to 9.6% hallucination with web access enabled. The o4-mini drops from 37.7% to 5.1%. Instead of relying on potentially stale training data, the model retrieves current information and grounds its response in external sources. For any business AI deployment, enabling web access should be the first configuration decision. [17]
2. RAG (Retrieval Augmented Generation) - Up to 71% Reduction
Connecting models to external knowledge bases - company documents, verified sources, databases - and instructing the model to generate responses grounded in retrieved content rather than parametric memory. The standard of care for enterprise document Q&A. [1]
3. Thinking/Reasoning Mode - 55-75% Reduction (Task-Dependent)
GPT-5 thinking mode drops HealthBench hallucination from 3.6% to 1.6%. But reasoning mode increases hallucination on summarization benchmarks. The impact depends entirely on the task type. Enable it for analysis. Disable it for summarization. [18]
4. Multi-Model Cross-Validation - the Structural Solution
Amazon's Uncertainty-Aware Fusion framework (ACM WWW 2025) combined multiple LLMs and found an 8% accuracy improvement over single-model approaches. The measured accuracy gain understates the practical value. In production, multi-model approaches catch errors no single model would flag - because each model has different training data, different biases, and different blind spots. [19]
Research published in PNAS on the "wisdom of the silicon crowd" shows that LLM ensembles can rival human crowd forecasting accuracy through simple aggregation. [20]
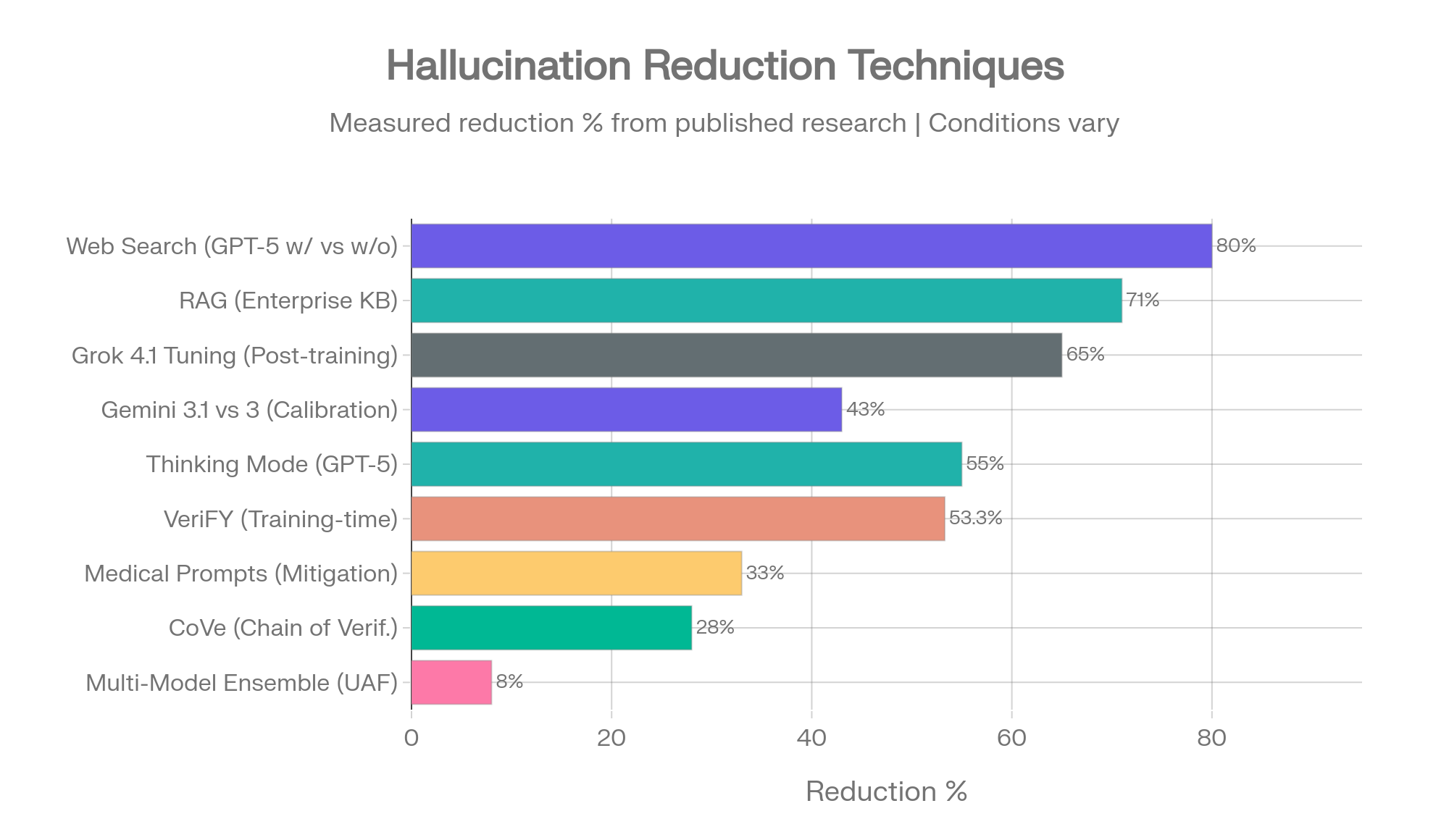
Hallucination reduction techniques ranked by measured impact. Multi-model cross-validation catches errors that no single-model check can. Sources: OpenAI, AllAboutAI, Amazon UAF, ACL 2024
The key finding across all techniques: no single intervention is sufficient. The most effective approach layers multiple methods - web search, retrieval augmentation, and cross-model verification working together. This is exactly the architecture behind Suprmind.
// Suprmind.ai
Why We Built Suprmind
Four Dots has been operating as a digital marketing agency since 2013. We've built six proprietary tools in that time - Dibz.me, Base.me, Reportz.io, FAII.ai, Fantom Click, and UberPress. When a tool we need doesn't exist, we build it. That's how we operate.
We started using AI across our entire workflow in 2023 - content, strategy, research, technical audits, client deliverables. And we kept catching fabrications. A statistic that sounded right but didn't exist. A citation to a study that was never published. A competitor analysis with invented market share figures. Occasionally a client would catch one before we did.
The standard response to this is "just verify everything." But we already tracked the cost: 4.3 hours per person per week is roughly what our own team was spending. Across an agency, that verification overhead was costing more than the AI tools themselves.
So we asked a different question. What if instead of one AI generating content and a human checking it, five AIs checked each other?
How Suprmind Works
Suprmind runs your question through five frontier AI models - GPT, Claude, Gemini, Grok, and Perplexity - in a structured sequence. Each model sees what the previous ones said before it responds.
A strategy decision, a research question, a recommendation your team needs to validate. Any question where accuracy matters.
Each one reads the full conversation so far - your question plus every previous AI's response - before generating its own answer. By the fifth model, you have perspectives that build on each other rather than five versions of the same thing.
When five models from different providers process the same question, they catch each other's fabrications. Models rarely invent the same false information. When one hallucinates, the others typically flag the inconsistency or provide conflicting data.
Where the models agree, you have high confidence. Where they disagree, you know exactly where to focus your human verification time. Instead of checking everything, you check the gaps.
Six Orchestration Modes for Different Decisions
Sequential Mode. Each AI builds on the previous responses. Best for deep analysis where iterative refinement matters.
Debate Mode. AIs argue opposing positions with rebuttals. Best for validating a strategy before committing resources.
Red Team Mode. Four attack vectors - technical, business, adversarial, edge cases. Each AI tries to break your idea from a different angle. Best for pre-launch risk assessment.
Research Mode. A four-stage pipeline: information retrieval, pattern analysis, critical validation, actionable synthesis. Best for comprehensive research where depth and accuracy both matter.
Fusion Mode. All five AIs respond simultaneously, then the platform synthesizes a unified answer. Best when you need multiple perspectives fast.
Targeted Mode. Direct questions to specific AIs via @mentions based on each model's strengths. Claude for legal, Grok for science, Perplexity for live data.
The Multi-Model Evidence
Multi-model verification is not a marketing concept. It's backed by published research across multiple institutions.
Amazon's Uncertainty-Aware Fusion (ACM WWW 2025): The framework combines multiple LLMs weighted by their accuracy and self-assessment quality. Key finding: different models excel on different question types, so combining them captures complementary strengths. The accuracy improvement was 8% over the best single model - but the error detection rate was substantially higher because models rarely produce the same hallucination. [19]
PNAS "Wisdom of the Silicon Crowd" (2025): LLM ensembles match human crowd forecasting accuracy through aggregation. The same principle that makes prediction markets more reliable than individual experts applies to AI models. [20]
Chain-of-Verification (ACL 2024): A four-step pipeline - generate response, plan verification questions, answer verification independently, refine output - achieves a 28% FActScore improvement. This is the verification logic built into Suprmind's sequential orchestration. [21]
No single model leads all domains. Across 42 knowledge topics tested in the AA-Omniscience benchmark, leadership shifts by domain: Claude leads in Law, Software Engineering, and Humanities. GPT leads in Business. Grok leads in Health and Science. An orchestration approach that routes to domain strengths and cross-validates weaknesses outperforms any single-model strategy. [22]
Five AI models. One conversation. Every claim cross-checked.
Built by Four Dots. Backed by research. See why professionals who can't afford to be wrong are switching to multi-model validation.
See Suprmind PlansRead the full research report -->
What Agency Owners Should Do Now
This section is specific to digital agencies because that's our world. We've lived through every stage of AI adoption, from excitement to overconfidence to catching errors to building systems that prevent them.
Audit Your AI Touchpoints
Map every place AI-generated content enters a client deliverable. Content briefs. Research reports. Competitive analyses. Strategy recommendations. Technical audits. Email copy. Ad copy. Social media. Every touchpoint where unverified AI output reaches a client or goes public is a liability exposure. Most agencies we talk to discover 2-3x more touchpoints than they initially estimate.
Stop Treating Verification as Optional
If 82% of AI production bugs come from hallucination, verification is not QA overhead - it's the core quality process. Build it into timelines and pricing. The $14,200 per employee per year in verification cost is real whether you account for it or not. [4]
Match Models to Domains
No single AI model leads across all knowledge areas. If your agency serves healthcare clients, using the same model you use for general content means you're operating at the average hallucination rate (15.6%) instead of the best available (4.3%). Model selection by domain is a free improvement that most agencies aren't making. [1]
Layer Your Defenses
The research is clear: no single technique is sufficient. The most effective approach combines web search access (73-86% reduction), domain-appropriate model selection (up to 3x improvement), and multi-model cross-validation (catches errors no single-model check would). This layered approach is what we built into Suprmind.
Educate Your Clients
Most business owners don't know that 47% of executives have acted on hallucinated AI content. That the legal profession is facing an acceleration of AI-fabricated citations in court filings. That the financial sector reports $50K-$2.1M per hallucination incident. These are not abstract risks - they're documented, measured, and growing. Agencies that can explain the problem and offer verification solutions earn trust that competitors relying on "we use AI" as a selling point cannot match.
Continue the Research
This page covers the business impact side of AI hallucinations. The deep data - model-by-model benchmarks, head-to-head comparisons, the reasoning paradox, detection tools, and historical trend analysis - lives on Suprmind and gets updated monthly.
Both resources are open to anyone. No signup required. We publish this research because transparency about AI limitations is the foundation of the case for multi-model verification - and because the industry needs more honest data, not more marketing claims about accuracy.
Live Benchmark Data
AI Hallucination Rates and Benchmarks - Complete Data
20+ frontier models across Vectara, AA-Omniscience, FACTS, HalluHard, and CJR. Color-coded cross-benchmark reference table. 57 sources. Updated monthly.
See the full data -->
Research Report
AI Hallucination Statistics: Research Report 2026
Benchmark methodology deep dives. Model-by-model profiles for GPT, Claude, Gemini, Grok, Perplexity. Downloadable CSV data assets.
Read the report -->
Sources and References
Data on this page is drawn from our comprehensive research published at Suprmind Hallucination Benchmarks, which tracks 57 primary sources. Key references cited on this page:
- AllAboutAI. "AI Hallucination Statistics and Research Report 2025-2026." Primary compilation source for domain-specific rates, business impact figures ($67.4B), and historical progression data.
- Deloitte. "Global AI Survey 2025." Source for executive decision-making statistics (47% made decisions on unverified AI content).
- Forrester. "Enterprise AI Cost Analysis 2025." Source for per-employee verification cost data ($14,200/year, 4.3 hours/week).
- Testlio. "AI Testing and Quality Report 2025." Source for production AI bug statistics (82% from hallucinations, 39% chatbot rework rate).
- MIT Research. "AI Confidence and Hallucination Correlation Study." January 2025. Finding: models use 34% more confident language when generating incorrect information.
- Gartner. "Hallucination Detection Tools Market Report 2025." Source for 318% market growth figure and $12.8B investment total.
- Charlotin, D. "Legal Citation Hallucination Database." 120+ documented cases of AI-hallucinated legal citations.
- Business Insider. Court ruling tracker: 10 cases (2023), 37 (2024), 73 (first 5 months 2025), 50+ (July 2025 alone).
- Stanford RegLab / Stanford Human-Centered AI Institute (HAI). "Legal AI Hallucination Study." hai.stanford.edu
- ECRI. "Top 10 Health Technology Hazards for 2025." AI risks listed as #1.
- FDA. AI-enhanced medical device data: 1,357 authorized, 60 involved in 182 recalls, 43% within first year.
- MedRxiv. "Medical Case Hallucination Study 2025." 64.1% without mitigation, 43.1% with mitigation.
- Industry reports (aggregated): 78% of financial firms deploy AI; SEC $12.7M in fines; $50K-$2.1M per incident.
SEC enforcement data, 2024-2025. - Xu, Z. et al. "Hallucination is Inevitable: An Innate Limitation of Large Language Models." arXiv, 2024. arxiv.org
- Karpowicz, M. "On the Fundamental Impossibility of Hallucination Control in Large Language Models." arXiv, 2025. arxiv.org
- OpenAI / Computerworld. "OpenAI admits AI hallucinations are mathematically inevitable." computerworld.com
- OpenAI. "GPT-5 System Card" and "o3/o4-mini System Card." Browse-on vs browse-off hallucination measurements.
- OpenAI. GPT-5 HealthBench data: thinking mode reduces hallucination from 3.6% to 1.6%.
Vellum. "GPT-5 Benchmarks." vellum.ai - Luo, Y. et al. "Uncertainty-Aware Fusion: An Ensemble Framework for Mitigating Hallucinations in Large Language Models." Amazon / ACM WWW 2025. arxiv.org
- Schoenegger, P. et al. "Wisdom of the silicon crowd: LLM ensemble prediction capabilities rival the human crowd." PNAS / PMC, 2025. pmc.ncbi.nlm.nih.gov
- Dhuliawala, S. et al. "Chain-of-Verification Reduces Hallucination in Large Language Models." ACL 2024 Findings. aclanthology.org
- Artificial Analysis. "AA-Omniscience Benchmark." November 2025 - February 2026. Domain-specific model leadership data. artificialanalysis.ai
Complete source list with 57 references: Suprmind Hallucination Benchmarks - Full References
Want to see multi-model verification in action?
Send a question to five frontier AIs. Watch them build on each other's responses. See where they agree - and where they don't.
Try Suprmind Free