 SEARCH
SEARCH

Wikipedia’s Search Engine Will Not Rival Google
Wikimedia Foundation, the parent organization of Wikipedia and several other open knowledge projects, recently announced a plan to build a new search engine with an aim to democratize online content. In September 2015, the project received a $2.5M grant from John S. and James L. Knight Foundation to build “the Internet’s first transparent engine,” whose purpose will be:
“To advance new models for finding information by supporting stage one development of the Knowledge Engine by Wikipedia, a system for discovering reliable and trustworthy public information on the Internet.”
Despite the fact that the project’s wiki clearly states Wikimedia is not building a general-purpose search engine to compete with Google, such doubts have been raised by both media and Wikipedia board members. Namely, in his recent Signpost article, Wikipedia editorial board member notes that the conceptual directions for discovery of Wikipedia’s new engine, which are presented on these slides, unmistakably look like Google-style search.
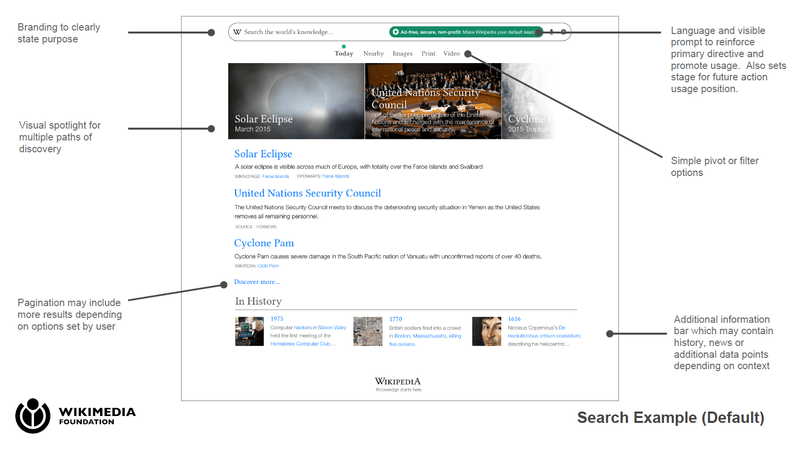
Source: https://en.wikipedia.org/wiki/Wikipedia:Wikipedia_Signpost/2016-02-10/Special_report
In addition to the design, the questions have been raised in relation to the sources of information that will be included in search. Referring to this issue, the project’s wiki suggests that the engine will also use information sources from other channels such as OpenStreetMap and other data sets that Wikipedia communities decide to use.
“The goal is to expand the amount of knowledge and expand the context beyond just textual search. We want to begin by showcasing content from other wiki projects including appropriate languages based on query input.”
Evidently, such data sources are entirely different from the ones Google uses in its own engine to offer general-purpose search results. In fact, a large portion of concerns as to whether or not Wikipedia’s Knowledge Engine will become the next Google is based on Jimmy Wales’s previous statements that he’ll try to revive his search project that failed in 2009. Eight years ago, Wikipedia’s co-founder launched a for-profit search engine, but was forced to shut it down only after a year.
After this failure, Wales suggested: “I will return again and again in my career to search, either as an investor, a contributor, a donor, or a cheerleader,” which partly encouraged the global media to associate the Knowledge Engine with this previous decision of his. However, as a Wikipedia spokesperson later confirmed for The Next Web:
“We do not have plans to build a new search engine: our objective is to improve people’s ability to find content across Wikipedia and the Wikimedia projects.”
Even after this explanation, the discussions about the project and its potential impact on the future of search continue to be a burning topic on the web. Guardian’s Seth Finkelstein, for example, commented on the strange relationship Google and Wikimedia Foundation Board have had:
“Now, the following remarks are purely speculative and the product of a very jaded and cynical person. Given Wales’s previous Wikia Search project, and the extensive Google connections with the current Wikimedia Foundation Board, I would be extremely wary that this project exists to help Google in further improving its search results (that’s indeed not competing with Google!). The spam and junk battle is ongoing.”
While the initiative for a non-commercial search engine is definitely a needed one in the world where Google dictates how we see the web content, the exact way the Knowledge Engine will change this issue is not really clear. With limited data sets and lots of speculations about its real purpose, it may only be more difficult for Wikimedia Foundation to properly present the project to the highly active online audience. After all, it will probably take years until its completed and by then the world of search is likely to change in many different ways.





